Neural Networks and Deep learning
Neural networks
A neural network just like regression or an SVM model, is a mathematical function:
The function
where
where
Multilayer Perceptron
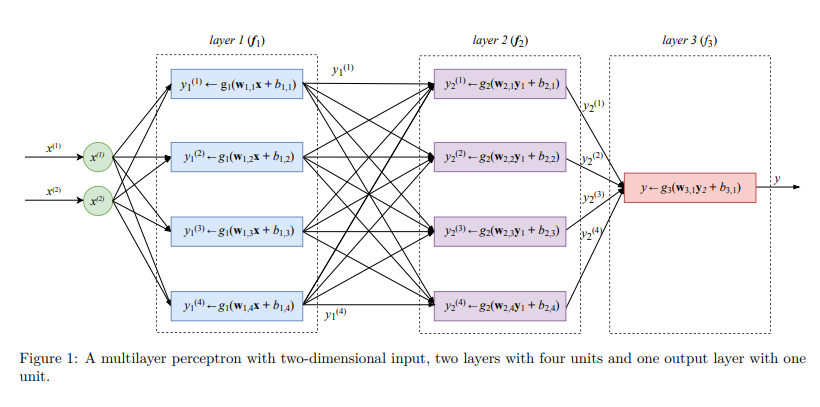
Feed-forward Neural Network Architecture
Feed-forward neural network architecture is a widely popular architecture used in ANN that process data in a feed forward manner. Two very popular activation functions are logistic function, tanh and ReLU .
Deep Learning
Deep learning refers to training neural networks with more than two non-output layers. The two biggest challenges were referred to as the problems of exploding gradient and vanishing gradient as gradient descent was used to train the network parameters.
To update the values of parameters in neural networks the algorithm called backpropagation is typically used. Backpropagation is an efficient algorithm for computing gradients on a neural networks using the chain rule. Chain rule is used to calculate partial derivatives of a function. During gradient descent, the neural network’s parameters receive an update proportional to the partial derivative of the cost function with respect to the current parameter in each iteration of training.
Convolutional Neural network
A convolutional neural network (CNN) is a special kind of FFNN that significantly reduces the number of parameters in a deep neural network with many units without losing too much in the quality of the model. CNNs have found applications in image and text processing where they beat many previously established benchmarks. Because CNNs were invented with image processing in mind.
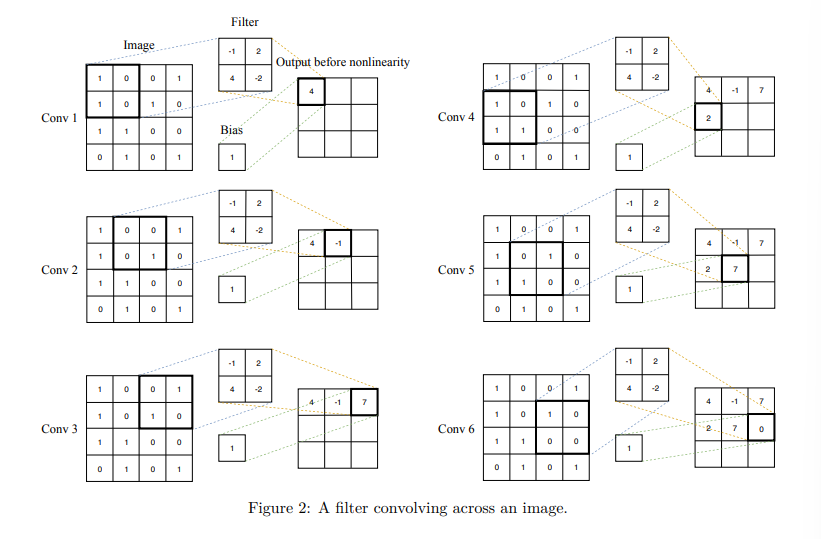
In CNNs, a small regression model looks like the one in the multilayer perception image. To detect some pattern, a small regression model has to learn the parameters of a matrix
If the CNN has one convolution layer following another convolution layer, then the subsequent layer
In computer vision, CNNs often get volumes as input, since an image is usually represented by three channels: R, G, and B, each channel being a monochrome picture
Recurrent neural network
Recurrent neural networks (RNNs) are used to label, classify, or generate sequences. A sequence is a matrix, each row of which is a feature vector and the order of rows matters. Labeling a sequence means predicting a class to each feature vector in a sequence. Classifying a sequence means predicting a class for the entire sequence. Generating a sequence means to output another sequence (of a possibly different length) somehow relevant to the input sequence.
The idea behind RNN is that each unit u of recurrent layer
- A vector of outputs from the previous layer
- A vector of state from this same layer
from the previous time step. 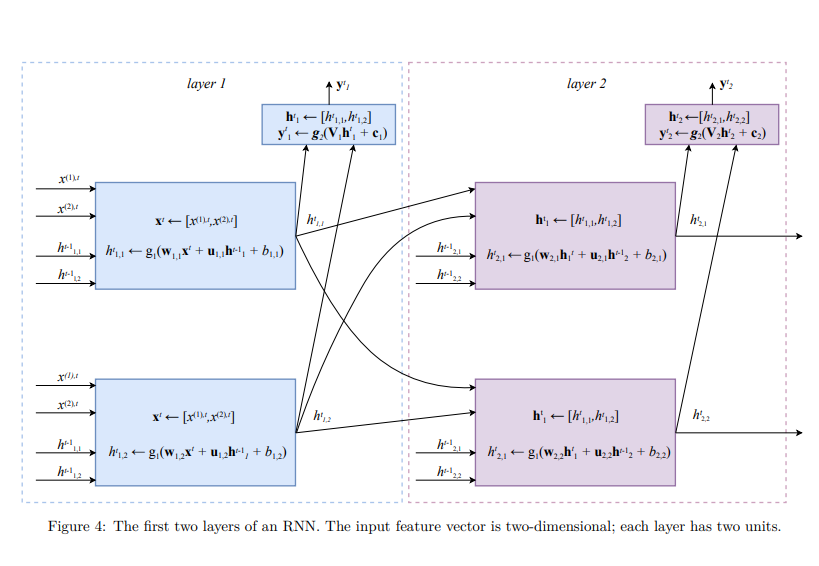 In an RNN, the input example is “read” by the neural network one feature vector at a timestep. The index
In an RNN, the input example is “read” by the neural network one feature vector at a timestep. The index denotes a timestep. To update the state at each timestep in each unit u of each layer we first calculate a linear combination of the input feature vector with the state vector of this same layer from the previous timestep, . The linear combination of two vectors is calculated using two parameter vectors and a parameter . The value of is then obtained by applying an activation function g1 to the result of the linear combination. A typical choice for function is . The output is typically a vector calculated for the whole layer at once. To obtain , we use an activation function that takes a vector as input and returns a different vector values calculated using a parameter matrix and the parameter vector . A typical choice for is the softmaxfunction.
The softmax function is a generalization of the sigmoid function to multidimensional data. It has the property that
The values of
Both
Another problem RNNs have is that of handling long-term dependencies. As the length of the input sequence grows, the feature vectors from the beginning of the sequence tend to be “forgotten,” because the state of each unit, which serves as network’s memory, becomes significantly affected by the feature vectors read more recently. Therefor in text or speech processing, the cause-effect link between distant words in a long sentence can be lost.
The most effective RNNs used in practice are gated RNNs. These include LSTM and GRUs.
Let’s look at the math of a GRU unit on an example of the first layer of the RNN (the one that takes the sequence of feature vectors as input). A minimal gated GRU unit u in layer l takes two inputs: the vector of the memory cell values from all units in the same layer from the previous timestep, ht≠1 l , and a feature vector xt . It then uses these two vectors like follows (all operations in the below sequence are executed in the unit one after another):
where
A gated unit takes an input and stores it for some time. This is equivalent to applying the identity function (f(x) = x) to the input. Because the derivative of the identity function is constant, when a network with gated units is trained with backpropagation through time, the gradient does not vanish.