Problems and Solutions
Kernel regression
Kernel regression is a non-parametric method. The model is based on the data itself. in its simplest form, in kernel regression we look for a model like this :
This function k(
The value b is a hyperparameter that we tune using the validation set.
Multiclass Classification
In multiclass classification, the label can be one of the C classes :
for all softmax function.
One Class Classification
One-class classification, also known as unary classification or class modeling, tries to identify objects of a specific class among all objects, by learning from a training set containing only the objects of that class. There are several one-class learning algorithms. The most widely used in practice are one-class Gaussian, one-class kmeans, one-class KNN, one class SVM. The idea behind the one-class gaussian is that we model our data as if it came from a Gaussian distribution, more precisely multivariate normal distribution (MND). The probability density function (pdf) for MND is given by the following equation:
where
Multi-label Classification
Ensemble Learning
Ensemble learning is a learning paradigm that, instead of trying to learn one super-accurate model, focuses on training a large number of low-accuracy models and then combining the predictions given by those weak models to obtain a high-accuracy meta-model. Low-accuracy models are usually learned by weak learners, that is learning algorithms that cannot learn complex models, and thus are typically fast at the training and at the prediction time. The most frequently used weak learner is a decision tree learning algorithm in which we often stop splitting the training set after just a few iterations. The obtained trees are shallow and not particularly accurate, but the idea behind ensemble learning is that if the trees are not identical and each tree is at least slightly better than random guessing, then we can obtain high accuracy by combining a large number of such trees. To obtain the prediction for input x, the predictions of each weak model are combined using some sort of weighted voting. The specific form of vote weighting depends on the algorithm, but, independently of the algorithm, the idea is the same: if the council of weak models predicts that the message is spam, then we assign the label spam to x. Two most widely used and effective learning algorithms are random forest and gradient boosting.
Random Forest
There are two ensemble learning paradigms: bagging and boosting. Bagging consists of creating many “copies” of the training data (each copy is slightly different from another) and then apply the weak learner to each copy to obtain multiple weak models and then combine them. The bagging paradigm is behind the random forest algorithm.
Gradient Boosting
Another effective ensemble learning algorithms is gradient boosting. To build a strong regressor, we start with a constant model f = f0 (just like we did in ID3):
Then we modify labels of each examples
where
Learning to Label Sequences
A sequence is one of the most frequently observed types of structured data.
In a sequence labeling , a labeled sequential example is a pair of list
The model called Conditional Random Fields(CRF) is a very effective alternative that often performs well in practice for the feature vectors that have many informative features. For example, imagine we have the task of named entity extraction and we want to build a model that would label each word in the sentence such as “I go to San Francisco” with one of the following classes:
Fact
CRF is an interesting method and can be seen as a generalization of logistic regression to sequences, however it has been outperformed by bidirectional deep gated RNN for sequence labelling.
Sequence-to-Sequence Learning
Sequence-to-sequence learning (often abbreviated as seq2seq learning) is a generalization of the sequence labeling problem. In seq2seq,
In seq2seq learning, the encoder is a neural network that accepts sequential input. The role of the encoder is to read the input and generate some sort of state (similar to the state in RNN) that can be seen as a numerical representation of the meaning of the input the machine can work with. The meaning of some entity, whether it be an image, a text or a video, is usually a vector or a matrix that contains real numbers. This vector (or matrix) is called in the machine learning jargon the embedding of the input.
The decoder in seq2seq learning is another neural network that takes an embedding as input and is capable of generating a sequence of outputs. To produce a sequence of outputs, the decoder takes a start of sequence input feature vector x(0) (typically all zeroes), produces the first output y(1), updates its state by combining the embedding and the input x(0), and then uses the output y(1) as its next input x(1).
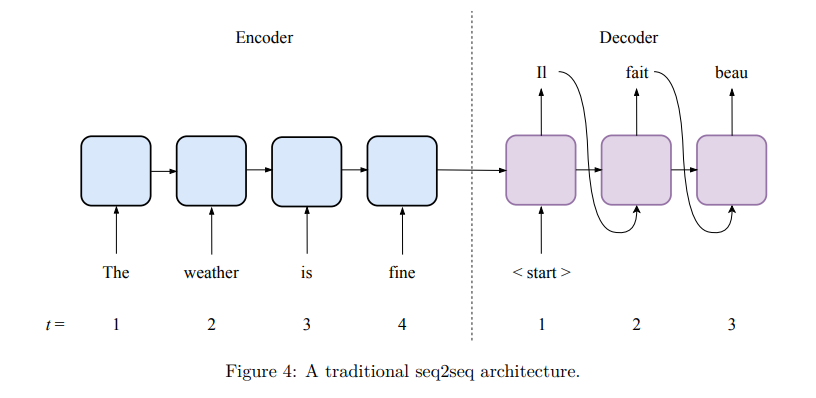
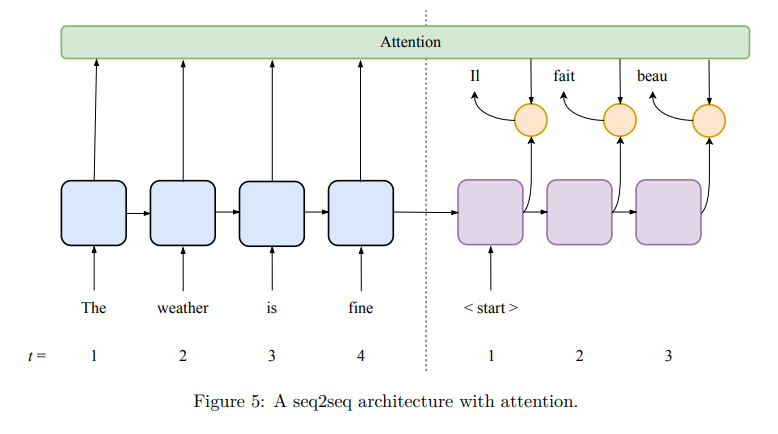
Both encoder and decoder are trained simultaneously using the training data. The errors at the decoder output are propagated to the encoder via backpropagation. More accurate predictions can be obtained using an architecture with attention. Attention mechanism is implemented by an additional set of parameters that combine some information from the encoder (in RNNs, this information is the list of state vectors of the last recurrent layer from all encoder time steps) and the current state of the decoder to generate the label. That allows for even better retention of long-term dependencies than provided by gated units and bidirectional RNN. A seq2seq architecture with attention is given below :
Active Learning
Active learning is an interesting supervised learning paradigm. It is usually applied when obtaining labeled examples is costly. There are multiple strategies of active learning.
- data density and uncertainty based
- support vector-based
Semi-Supervised Learning
In semi-supervised learning (SSL) we also have labeled a small fraction of the dataset; most of the remaining examples are unlabeled. Our goal is to leverage a large number of unlabeled examples to improve the model performance without asking an expert for additional labeled examples.
One shot learning
n one-shot learning, typically applied in face recognition, we want to build a model that can recognize that two photos of the same person represent that same person. If we present to the model two photos of two different people, we expect the model to recognize that the two people are different.
One way to build such a model is to train an SNN. to train a an SNN we use the triplet loss function..
we have a neural network model that can take a picture of a face as input and output an embedding of this picture. The triplet loss for one example is defined as
The cost function is defined as the average triplet loss:
where
Zero shot learning
In zero-shot learning (ZSL) we want to train a model to assign labels to objects. The most frequent application is to learn to assign labels to images.